Optimizing Email Batch API with bulk inserts
This blog post was originally published on the GoDaddy Engineering Blog.

Rails 6 introduced the insert_all ActiveRecord API for inserting multiple records into the database with a single SQL INSERT statement. It has an option to select the returning columns, but it is available only for PostgreSQL using its RETURNING SQL clause and not MySQL. This blog post explores how we optimized our Email Batch API by using Rails bulk inserts with MySQL and the details of calculating the auto-incrementing IDs for records.
Improving Our Email API
Our Email API has a multi-tenant architecture providing a database for each customer. It accepts millions of emails daily and provides a Batch API for enqueuing up to 50 messages per single batch request. The Batch API inserts these records one by one, enqueues background workers to build and deliver the emails, and returns the message IDs to the client for an eventual status check later.
Our change aims to improve the Batch API performance by inserting messages in bulk while preserving the original API design and returning the message IDs to the client. Our API runs on-premise using MySQL and in AWS using Aurora MySQL, and the change must be compatible with both.
MySQL Information Functions
Although MySQL does not support a RETURNING clause, it provides LAST_INSERT_ID() and ROW_COUNT() functions that can help us calculate the auto-incrementing ID values from the connection session. The LAST_INSERT_ID() function returns the first automatically generated value successfully inserted for an AUTO_INCREMENT column in a table. And the ROW_COUNT() function returns the number of rows affected by the previous SQL statement.
So, it seems simple enough to calculate the auto-incrementing IDs based on these two values.
AUTO_INCREMENT Handling in InnoDB
Before we go any further, we need to review the innodb-auto-increment-handling because the type of inserts, the lock mode, and the replication type can have implications on whether the IDs will be consecutive and be the same on the replicas as on the source. We need to ensure the generated IDs are without any gaps to be able to calculate their values with the functions reliably.
The type of multiple-row inserts we do are:
INSERT INTO `messages` (`template_id`, `params`, `created_at`, `processed`)
VALUES (NULL, 'content', '2022-02-04 15:12:24', FALSE),
(NULL, 'content', '2022-02-04 15:12:24', FALSE)
These inserts fall into the category of simple inserts:
Statements for which the number of rows to be inserted can be determined in advance (when the statement is initially processed). This includes single-row and multiple-row INSERT and REPLACE statements that do not have a nested subquery, but not INSERT … ON DUPLICATE KEY UPDATE.
There are three types of lock modes for MySQL: traditional (0), consecutive (1), and interleaved (2). If the only statements we execute are “simple inserts,” then there are no gaps in the numbers generated for any lock mode. We use the “consecutive” lock mode with MySQL 5.7:
irb(main):001:0> ActiveRecord::Base.connection.execute("SELECT @@innodb_autoinc_lock_mode;").to_a
=> [[1]]
There are three types of binary log formats: STATEMENT, ROW, and MIXED. When using statement-based replication and interleaved lock mode combination, there are no guarantees for auto-increment values to be the same on the replicas as on the source. But, when using row-based or mixed-format replication and any auto-increment lock mode, auto-increment values will be the same on the replicas as on the source. We run our binary log in MIXED format.
2.7.4 :001 > ActiveRecord::Base.connection.execute("SHOW VARIABLES LIKE 'binlog_format';").to_a
=> [["binlog_format", "MIXED"]]
Here’s the messages table schema we do bulk inserts against:
CREATE TABLE `messages` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`template_id` int(11) DEFAULT NULL,
`params` mediumtext CHARACTER SET utf8mb4,
`created_at` timestamp NOT NULL,
`processed` tinyint(1) DEFAULT '0',
PRIMARY KEY (`id`),
KEY `index_messages_on_template_id` (`template_id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8 ROW_FORMAT=COMPRESSED KEY_BLOCK_SIZE=8
Thread Safety of LAST_INSERT_ID()
Given that LAST_INSERT_ID() isolation is per-connection and Rails’s ConnectionPool is thread-safe, using LAST_INSERT_ID() is safe with our case.
The ID that was generated is maintained in the server on a per-connection basis. This means that the value returned by the function to a given client is the first AUTO_INCREMENT value generated for most recent statement affecting an AUTO_INCREMENT column by that client. This value cannot be affected by other clients, even if they generate AUTO_INCREMENT values of their own. This behavior ensures that each client can retrieve its own ID without concern for the activity of other clients, and without the need for locks or transactions.
Bulk Insert and Calculate Auto-Incrementing IDs
To convert the individual Rails model saves to a single bulk insert, we collect the attributes for all models before the final bulk insert. The following code with inline comments shows how we collect the models’ attributes.
attributes = messages_params.map do |message_params|
# Initialize Message object
message = Message.new(message_params: message_params)
# Set timestamps
Message.all_timestamp_attributes_in_model.each do |name|
message._write_attribute(name, Message.current_time_from_proper_timezone)
end
# Run the necessary model callbacks
[:validation, :save, :create].each { |kind| message.run_callbacks(kind) }
# Collect message attributes for bulk insert
attribute_names = Message.column_names - [Message.primary_key]
attribute_names.each_with_object({}) do |name, object|
object[name] = message._read_attribute(name)
end
end
Once we’ve built the array of attributes, we can call insert_all!.
Message.insert_all!(attributes)
We use insert_all! instead of insert_all for the bulk insert so if an issue occurs, it fails the whole insert, and no rows are inserted. For instance, insert_all! raises the ActiveRecord::RecordNotUnique error if any rows violate a unique index when it’s present on the table.
After inserting the records, we can calculate the auto-incrementing IDs by retreiving the LAST_INSERT_ID() value from the Mysql2::Client object using the last_id method:
mysql_client = Message.connection.instance_variable_get(:@connection)
last_id = mysql_client.last_id
When inserting multiple rows using a single INSERT statement, the last_id returns only the value generated for the first inserted row.
To get the ROW_COUNT() function value, we can call the affected_rows method on the Mysql2::Client, but since the IDs are consecutive numbers, we can simply add the loop index to the last_id and set the message ID:
messages.each_with_index do |message, index|
message.id = last_id + index
end
Performance Improvements
By deploying this change to our Email API running with MySQL 5.7, we saw a decrease of about 35% for the average transaction duration time of the Batch API request. The time decrease percentage is for the Batch API request and not just the MySQL insert time.
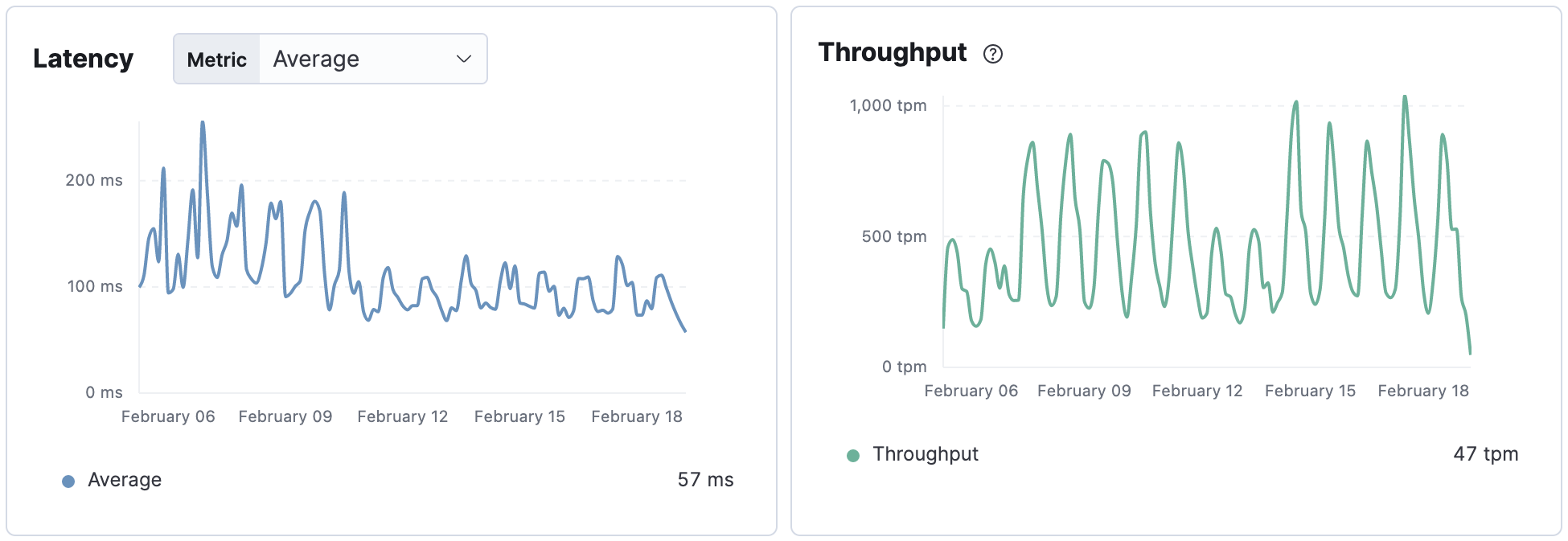
And for the Email API in AWS running with Aurora MySQL 5.7, the change decreased the average transaction duration time of the Batch API request by about 65%.
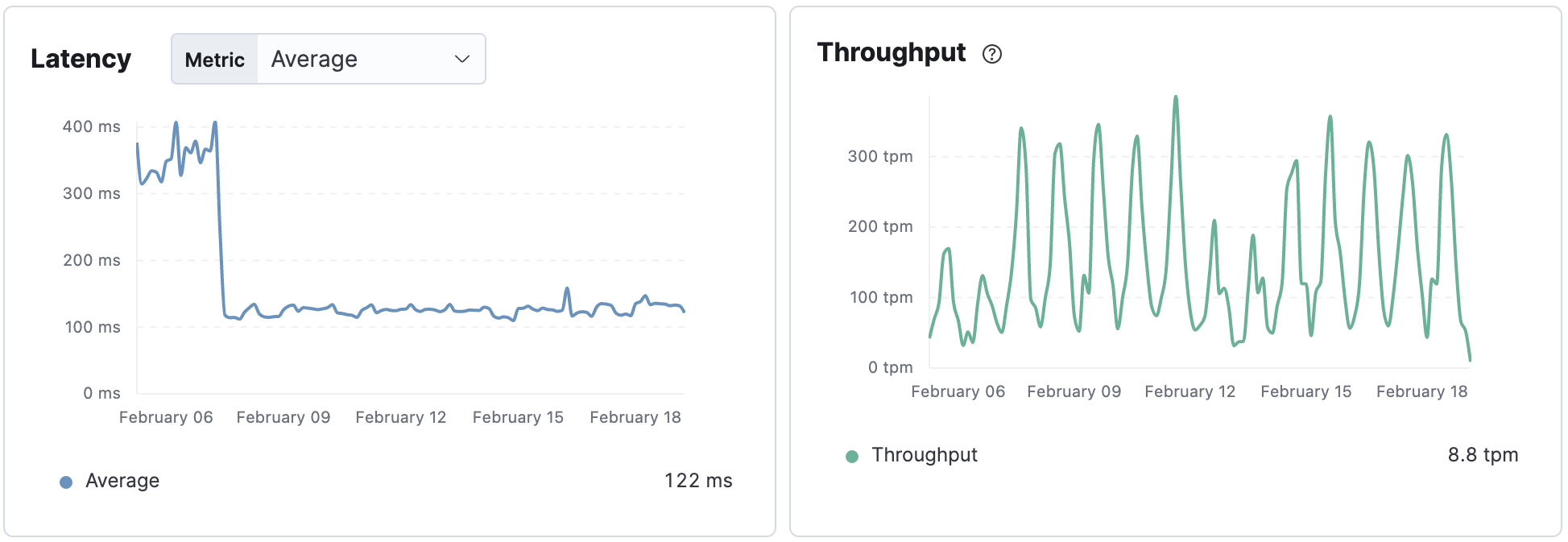
Summary
MySQL does not support a RETURNING clause for getting the auto-incrementing IDs for bulk inserts, but it provides the LAST_INSERT_ID() information function that helps us calculate them. By introducing bulk inserts, we significantly improved the transaction duration times of our Email Batch API requests. The change had a more significant effect on AWS Aurora MySQL, presumably due to its engine optimization. A simpler application model with minimal callbacks and validation logic makes introducing such a change more feasible.
*) Cover Photo Attribution: Photo by Marek Piwnicki: https://www.pexels.com/photo/train-in-motion-8991549/
