Implementing a custom Redis and in-memory bloom filter
This blog post was originally published on the GoDaddy Engineering Blog.
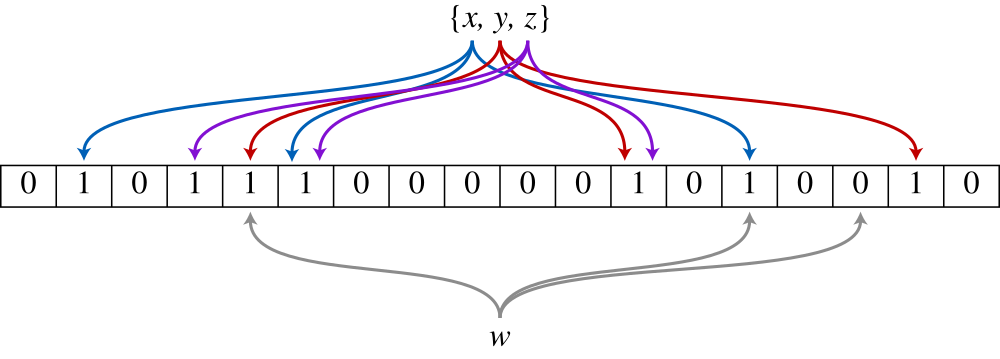
In our email marketing and delivery products (GoDaddy Email Marketing and Mad Mimi) we deal with lots of data and work with some interesting data structures like bloom filters. We made an optimization that involved replacing an old bloom filter built in-memory and stored on Amazon S3 with a combination of a Redis bloom filter and an in-memory bloom filter. In this blog post we’ll go through the reasoning for this change as well as the details of the bloom filter implementation we landed on. Let’s first start with a brief introduction to bloom filters.
What is a bloom filter?
A Bloom filter is a space-efficient probabilistic data structure, designed to test whether an element is a member of a set. Because of its probabilistic nature, it can guess if an element is in a set with a certain precision or tell for sure if an element is not in a set. That is an important detail to design around as we’ll see later. If you’re curious about the math involved, check out this blog post for more details.
What is the real problem we are solving?
In our email delivery products, each plan places limit on the number of unique contacts our customers can send emails to in a billing cycle. An interesting abuse scenario happens when a customer uploads a list of email addresses, sends a campaign to that list, deletes the list, and then imports another list with different email addresses and sends another campaign. We call this scenario “deleting and replacing” and to prevent it we need to keep a history of contacts that have received emails in a billing cycle.
The naive solution
The naive solution would be to check against the history of delivered emails in a billing cycle. While that might work for smaller data sets, it causes a performance problem when dealing with billions of contacts. That is where the opportunity for using the bloom filter data structure emerges.
Initial bloom filter implementation
Initially, we used the C-implementation from bloomfilter-rb by building a bloom filter in-memory and uploading it to Amazon S3.
There were issues with this approach, the two most important ones being:
- concurrency: sending multiple campaigns at the same time overrides the filter
- slow updates / restricted to bulk updates: fetching files from S3 is not fast and updating the filter for one-off sends is expensive and not doable
With the re-design, we need a solution that will solve these problems.
Bloom filter implementation
Our bloom filter will have as a dependency our User model. Let’s say the User model has three attributes: id, max_contacts and billing_cycle_started_at:
User = Struct.new(:id, :max_contacts, :billing_cycle_started_at)
user = User.new(1, 500, Time.new(2018, 8, 01, 10, 0, 0, 0))
Here is our bloom filter implementation:
require 'zlib'
class BloomFilter
# http://www.igvita.com/2008/12/27/scalable-datasets-bloom-filters-in-ruby/
# 10 bits for 1% error approximation
# ~5 bits per 10 fold reduction in error approximation
BITS_PER_ERROR_RATE = {
1 => 10,
0.1 => 15,
0.01 => 20
}
HASH_FUNCTIONS_COEFICIENT = 0.7 # Math.log(2)
attr_reader :error_rate
def initialize(user, error_rate: )
@user = user
@error_rate = error_rate
end
def indexes_for(key)
hash_functions.times.map { |i| Zlib.crc32("#{key.to_s.strip.downcase}:#{i+seed}") % size }
end
def hash_functions
@hash_functions ||= (bits * HASH_FUNCTIONS_COEFICIENT).ceil.to_i
end
def seed
@seed ||= since.to_i
end
def since
@since ||= @user.billing_cycle_started_at
end
def size
@size ||= bits * @user.max_contacts
end
def bits
@bits ||= BITS_PER_ERROR_RATE.fetch(error_rate)
end
def fingerprint
@fingerprint ||= [@user.id, @user.max_contacts, seed].join('.')
end
end
The most important part of the bloom filter is the method that generates the indexes for a given key, indexes_for(key).
Here’s an example usage:
bloom_filter = BloomFilter.new(user, error_rate: 1)
bloom_filter.indexes_for('user1@example.com')
# [2872, 110, 3108, 2498, 4409, 751, 2861]
bloom_filter.indexes_for('user2@example.com')
# [3992, 2262, 1788, 1970, 3185, 4135, 4957]
As a hashing function we use CRC32 with a custom seed per user that is the billing_cycle_started_at and the number of hashing functions based on the error rate (in this example we use an error rate of 1%).
For the bloom filter to return consistent hashing indexes during a user’s billing cycle, the input parameters it depends on (error_rate, @user.billing_cycle_started_at and @user.max_contacts) should not change for the billing cycle until it gets reset. That is the fingerprint that, as we’ll see later, we’ll use as a redis key for the Redis bloom filter.
Redis bloom filter
Redis supports getbit and setbit operations for the String type that make the individual updates simple. There is a special data type for bloom filters called rebloom if you want to explore it, but here we’ll just use a standard Redis type.
Here is our Redis bloom filter implementation:
require 'redis'
class RedisBloomFilter
MAX_TTL = 31 * 24 * 60 * 60 # max days in a month
def initialize(user)
@user = user
end
def insert(keys)
existing_indexes = redis.pipelined do
keys.each do |key|
bloom.indexes_for(key).map { |index| redis.setbit(filter_key, index, 1) }
end
end
new_keys_count = keys.length.times.count { |i|
existing_indexes[i * bloom.hash_functions, bloom.hash_functions].include?(0)
}
total = redis.incrby(counter_key, new_keys_count)
if total == new_keys_count
redis.expire(filter_key, MAX_TTL.to_i)
redis.expire(counter_key, MAX_TTL.to_i)
end
end
def count
redis.get(counter_key).to_i
end
def include?(key)
values = redis.pipelined do
bloom.indexes_for(key).map { |index| redis.getbit(filter_key, index) }
end
!values.include?(0)
end
def field
redis.get(filter_key)
end
private
def redis
@redis ||= Redis.new
end
def bloom
@bloom ||= BloomFilter.new(@user, error_rate: 1)
end
def filter_key
@filter_key ||= "bloom:filter:#{key_suffix}"
end
def counter_key
@counter_key ||= "bloom:counter:#{key_suffix}"
end
def key_suffix
@key_suffix ||= bloom.fingerprint
end
end
The RedisBloomFilter uses the BloomFilter implementation to produce the indexes that it manipulates in Redis. It also implements a counter of how many unique elements are added to the filter by increasing the count when it detects a unique insert. Using an error rate of 1% for the bloom filter means that the count can be for 1% lower than the actual count and in our case that is totally fine as we allow for a bigger grace overage to customer plans. It uses redis pipelined that sends operations in batch to avoid latency and improve performance by about 5-6 times. It also sets a TTLs on the keys to expire them after a month and it exposes the field for the in-memory filter.
Here’s an example usage:
redis_bloom_filter = RedisBloomFilter.new(user)
redis_bloom_filter.insert(['user1@example.com', 'user2@example.com'])
redis_bloom_filter.count
# => 2
redis_bloom_filter.include?('user1@example.com')
# => true
redis_bloom_filter.include?('user2@example.com')
# => true
redis_bloom_filter.include?('user3@example.com')
# => false
In-memory Bloom filter
With the Redis implementation we solved half of the problem. We have a way to concurrently and quickly add elements to the bloom filter in Redis, but we still need a way to check if a bloom filter could accept a given set of elements without actually inserting the elements in the filter. This is useful when we want to prevent a list import before importing the list or stop a campaign from sending before starting it.
To achieve that, we need an in-memory filter that we can initialize with the state of the Redis bloom filter and bitarray can help us with that. We have an important PR that changes the storage representation i.e. the bits order in bitarray to match the way Redis stores them internally and a way to initialize a bitarray with a given field. To test it, you can fetch the BitArray that includes that patch from here.
Here is the implementation of the in-memory bloom filter:
class TemporaryBloomFilter
def initialize(user)
@user = user
@bloom = BloomFilter.new(@user, error_rate: 1)
@redis_filter = RedisBloomFilter.new(@user)
@count = @redis_filter.count
end
def count
@count
end
def insert(keys)
keys.each do |key|
previous_indexes = @bloom.indexes_for(key).map { |index|
value = bit_array[index]
bit_array[index] = 1
value
}
@count += 1 if previous_indexes.include?(0)
end
end
def include?(key)
!@bloom.indexes_for(key).map { |index| bit_array[index] }.include?(0)
end
def over_limit?
plan_over_limit_count > 0
end
def plan_over_limit_count
@count - @user.plan_contacts
end
private
def bit_array
@bit_array ||= prepare_bit_array
end
def prepare_bit_array
field = @redis_filter.field.to_s
current_field_length = field.length
max_field_length = (@bloom.size / 8 + 1)
if current_field_length < max_field_length
field += "\0" * (max_field_length - current_field_length)
end
BitArray.new(@bloom.size, field)
end
end
And an example usage:
temporary_bloom_filter = TemporaryBloomFilter.new(user)
temporary_bloom_filter.insert(['user3@example.com', 'user4@example.com', 'user5@example.com'])
temporary_bloom_filter.count
# => 5
temporary_bloom_filter.include?('user5@example.com')
# => true
temporary_bloom_filter.include?('user6@example.com')
# => false
Performance
Ruby’s in-memory implementation is few times slower than the C-implementation in bloomfilter-rb, but still fast enough as it can process 1 million items in 5-10 seconds both calculating hash functions and doing BitArray inserts.
total_items = 1_000_000
t1 = Time.now
bf = BloomFilter.new(user, error_rate: 1)
ba = BitArray.new(total_items)
total_items.times do |i|
bf.indexes_for("user#{i}@example.com").each do |j|
ba[j] = true
end
end
t2 = Time.now
puts t2-t1
# => 7.485282645
Redis performance is pretty solid as well. It can handle around 70-80k operations per second and when using pipelined mode for our batches of 350, we get 5-6 times more operations:
$ redis-benchmark -q -n 100000 -P 350
PING_INLINE: 373134.31 requests per second
PING_BULK: 421940.94 requests per second
SET: 369003.69 requests per second
GET: 396825.38 requests per second
INCR: 344827.59 requests per second
LPUSH: 362318.84 requests per second
LPOP: 389105.06 requests per second
SADD: 353356.91 requests per second
SPOP: 361010.81 requests per second
LPUSH (needed to benchmark LRANGE): 370370.34 requests per second
LRANGE_100 (first 100 elements): 61050.06 requests per second
LRANGE_300 (first 300 elements): 17494.75 requests per second
LRANGE_500 (first 450 elements): 11043.62 requests per second
LRANGE_600 (first 600 elements): 7965.59 requests per second
MSET (10 keys): 202839.75 requests per second
Conclusion
This custom implementation of a bloom filter turned out pretty solid and robust in our production environment. We have a Kibana dashboard monitoring the bloom filter updates over time giving us much better insights than our previous implementation.
